XML Sitemaps and robots.txt: Your Guide to Crawlability and Indexing
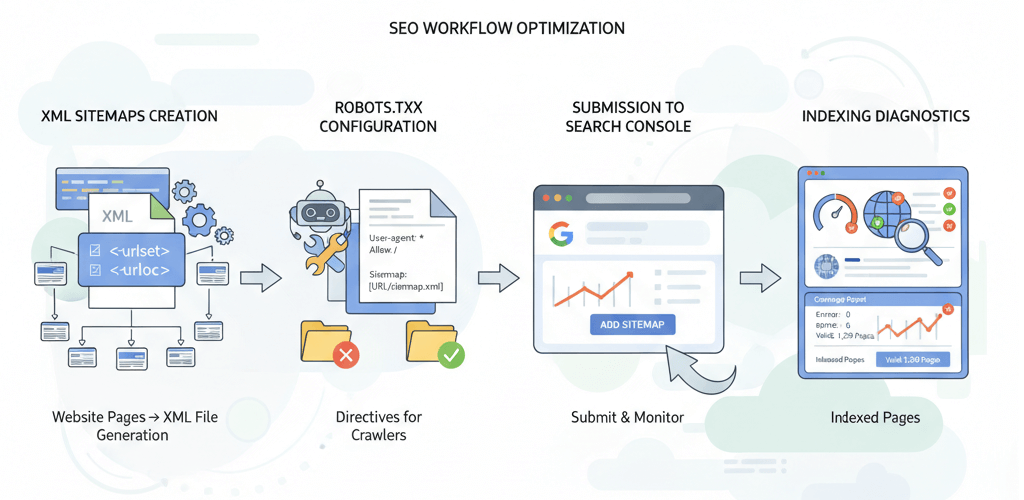
For a website to be found by users, search engines like Google and Bing must first "crawl" and "index" its pages. While a good content strategy and on-page SEO are crucial, two simple yet powerful files—the XML sitemap and the robots.txt file—act as a roadmap and a set of instructions for search engine crawlers. Misconfiguring either of these can lead to significant issues, from un-indexed pages to critical content being hidden from search results. This comprehensive guide will walk you through the process of creating, submitting, and troubleshooting these files to ensure your website's visibility. For a broader perspective on improving how search engines see your site, see our guide on Improving Website Crawlability and Indexing.
Understanding the Core Functions
The XML Sitemap: Your Website's Roadmap
An XML sitemap is a file that lists all the important pages on your website, making it easier for search engine crawlers to find and index them. It acts as a guide, especially for large websites or those with complex structures that may have pages that aren't easily discoverable through regular navigation. While a sitemap doesn't guarantee a page will be indexed, it is a crucial tool for guiding crawlers. This is a key part of any website audit.
The robots.txt File: Your Website's Rulebook
The robots.txt file, placed in the root directory of your website, is a text file that tells search engine crawlers which parts of your site they should and should not access. It’s an instruction manual for crawlers, but it's important to understand that it is a suggestion, not an enforcement. Malicious bots often ignore it, but it's respected by all major search engines. The proper use of this file can prevent the indexing of duplicate content, private directories, and other pages you don't want to appear in search results. For more details on the importance of this file, see our article on the Importance of robots.txt.
Step-by-Step Guide to XML Sitemaps
1. How to Generate a Sitemap
Manually creating a sitemap is only feasible for small, static websites. For most websites, especially those built on a CMS like WordPress, automation is key.
- For WordPress: The easiest way is to use a plugin like Yoast SEO or Rank Math. These plugins automatically generate and keep your sitemap updated as you add or remove content. You can usually find the sitemap at
yourdomain.com/sitemap_index.xml. - For Other Platforms: Most modern CMS platforms have a built-in sitemap generator. If yours doesn't, or if you have a custom-built site, you can use a free online sitemap generator tool. Just enter your website's URL, and it will crawl your site to create a file you can download and upload to your server's root directory.
2. How to Submit Your Sitemap to Google
Once your sitemap is created, you need to tell Google where to find it. This is done through Google Search Console.
- Log in to your Google Search Console account.
- In the left-hand menu, click on "Sitemaps."
- Enter the URL of your sitemap (e.g.,
https://webcare.sg/sitemap_index.xml). - Click "Submit." Google will then process the sitemap and inform you of any errors or a successful submission.
3. Troubleshooting Sitemap Issues
If Google Search Console reports errors, here are some common issues and their fixes:
- HTTP Errors: This means Google can't access your sitemap. Check if the URL is correct and if there are any server-side issues. For more on this, see our article on How to Fix Website Downtime and Server Errors.
- Incorrect URLs: Ensure that all the URLs in your sitemap are correct and resolve to a valid page. If you have broken links, it can cause problems. Our guide on Identifying and Fixing Broken Internal Links can help.
- Pages Not Indexed: If a page is in your sitemap but not being indexed, it could be due to a "noindex" tag on the page or a directive in your robots.txt file that is blocking it. You can learn more about why a page is not indexed in Google Search Console.
Step-by-Step Guide to robots.txt
1. How to Create and Configure the robots.txt File
The robots.txt file is a simple text file that you create and place in the root directory of your website (e.g., yourdomain.com/robots.txt).
- Allowing All Crawlers: To allow all search engines to crawl your entire site, use the following code:
User-agent: * Disallow: - Disallowing Specific Directories: To prevent crawlers from accessing a specific folder, use:
User-agent: * Disallow: /private/ Disallow: /admin/ - Specify Sitemap Location: It's a best practice to add the location of your sitemap in your robots.txt file, which helps crawlers find it easily:
Sitemap: https://webcare.sg/sitemap_index.xml
2. Troubleshooting robots.txt Issues
Misconfigured robots.txt files can be a huge problem. One wrong line can de-index your entire site. If you are experiencing issues with indexing, check these common problems:
- Accidental Disallow: A common mistake is a typo that results in a line like
Disallow: /which tells crawlers to avoid your entire site. Always double-check your file. This is similar to a redirect loop, which can also break your site. - Checking with Google's Tester: Use Google Search Console's "robots.txt tester" tool to verify your file. This tool will show you exactly what Google's crawler is being told to do on your site and can help you pinpoint any errors.
- Overlapping Rules: Ensure you don't have conflicting rules in your file that might confuse crawlers.
When to Call the Experts
While creating and managing these files is manageable for most, technical issues can arise. If your website is not being indexed, if you have a large site with complex a structure, or if you're dealing with a sudden drop in rankings that you suspect is related to crawling issues, it's time to seek professional help. A professional can use advanced diagnostic tools to pinpoint the exact cause of the issue, whether it's a server-side problem or a complex robots.txt directive. Attempting to fix these issues without proper knowledge can lead to further complications, similar to how DIY website fixes can sometimes make things worse.
If you’re still having trouble, don’t worry! WebCare SG is here to help. Contact us today for fast and reliable website fixes.
Related WebCare Solutions
Shopify Google Ads Conversion Tracking Broken? Try This
Is your Shopify store's Google Ads conversion tracking not working? Learn why issues arise with `checkout.liquid` restrictions and how to correctly implement tracking on the thank-you page to capture valuable sales data.

How to Secure Your Website Against Basic Threats
Learn how to secure your website against basic threats. Protect your online presence with these essential tips and steps.

When Should You Hire a Website Repair Expert?
Learn the key signs indicating it's time to bring in professional website repair experts to resolve complex or persistent issues.
Ready to get started?
Focus on your business while we fix your website. Contact WebCareSG today for fast, reliable solutions!
Whatsapp us on